-用語解説-
株式会社HPCソリューションズ
2012年11月15日
並列ファイルシステム、或いは分散ファイルシステムと呼ばれるものが最近のPCクラスタでは標準となっています。 これらは複数のサーバ、複数のストレージデバイスを仮想的に1ボリューム化し、更に共有ファイルシステムとしてサービスすることが出来ます。 並列ファイルシステムは大規模システムのものと思いがちですが、計算ノードが数十台以下の小さなシステムでも大きなサイズのファイルを扱うプログラムでは絶大な効果を発揮します。 最近では選択肢が増えたこともあり、規模が小さければそれに合わせた低コストの並列ファイルシステムを作ることも容易になりました。
この解説では並列ファイルシステムの代表的なものとしてLustre、GPFS、GlusterFS、Panasas ActiveStorを紹介したいと思います。(※Panasas ActiveStorはサーバなどハードウェアを含むアプライアンス製品ですが、独自の並列ファイルシステムを利用しているのでここで取り上げました。)
Lustre
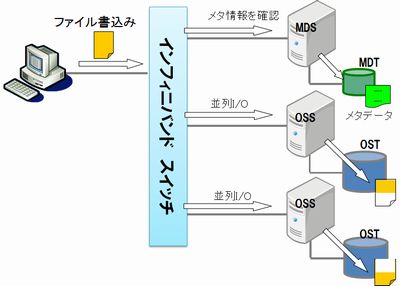
LustreはHPC分野で最も多く採用されている並列ファイルシステムです。 インフィニバンドをインターコネクトに使用することで広帯域幅を利用することが出来ます。 特にHPC分野ではMPI通信用のインターコネクトとしてインフィニバンドを採用することが標準的ですので、同じネットワークを共有することでコストを抑えることが出来ます。 Lustreは1台のメタデータサーバ(MDS)と複数のオブジェクトストレージサーバ(OSS)によって構成されます。 MDSはメタデータ領域(MDT)を持ち、MDTの性能と信頼性はLustreの要となるため、RAID-1、RAID-10などの構成にすることが多いです。 OSSはデータ領域(OST)を一つ以上もち、このOSTを集め仮想的に1ボリュームに見せます。 並列ファイルシステムで重要なのは複数のデータ領域をどの様に1ボリューム化するかということです。 Lustreの場合はRAID-0によく似たストライピング方式で1ボリューム化します。 つまり、ストライプサイズと呼ばれる大きさ(デフォルト4KB)にファイルを分割し、各OSTにばら撒きます。 こうすることで大きなファイルを高速に並列で書込み・読み出すことが可能になります。 しかしながら、ボリュームを構成するOSTのどれかが障害などで参照できなくなると、そのファイルは消失してしまうというリスクがあります。 Lustreの場合はストライプカウントを1にすることで、ファイルを分割せずに、ボリュームを構成するOSTのどれかにファイルを丸ごと保存する方式も取れます。 この場合にもどれかのOSTが破損すれば、そのOSTに格納されていたファイルは消失します。 Lustreの場合、ファイルシステム自身には耐障害機能を持ちません。 OSTをRAID-5やRAID-6などにして信頼性を確保します。 また、大規模なシステムではMDSやOSSをheartbeatなどを使ってHA構成にすることが多いです。 kernelにドライバをサーバ、クライアント共に組み込む必要があり、OSのセキュリティーアップデートについていくのは結構な手間になります。 Lustreはオープンソースですので、ソフトウェア自体の導入コストは0です。
GPFS
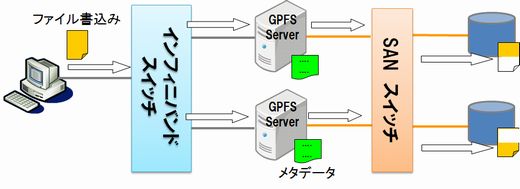
GPFS(General Parallel File System)はIBMの製品です。 歴史は古く、元々はPowerサーバのファイルシステムとして開発されました。 現在は、x86システムのLinux、Windowsでも利用でき、IBMのサポートを受けることが出来ます。 インターコネクトにはインフィニバンドを使用することが出来ます。 メタデータサーバは不要で、各サーバにメタデータが配布されます。 ハードウェア構成として、サーバはSANに接続し同じSANストレージを参照できるようにします。 これにより単一サーバ障害であれば別のサーバへボリュームのマウントを切り替えることが出来、高い耐障害性を持っています。 性能については、Lustreの様なストライピング機能をもっており、高速なファイルI/Oが可能です。 さらにボリュームのレプリケーションや各ボリュームに分散したファイルの平滑化(レベリング)などの機能を持ち、高機能なファイルシステムです。 kernelドライバは不要なため、OSアップデートなどへの対応は比較的容易です。 クライアント接続はGPFSのモジュールを使う方法とNFSマウントに対応しており、Linux以外のUNIXシステムなどでもNFS経由で利用できます。 今回ご紹介している中では、唯一Windows用のクライアントモジュールを持っています。
Panasas ActiveStor
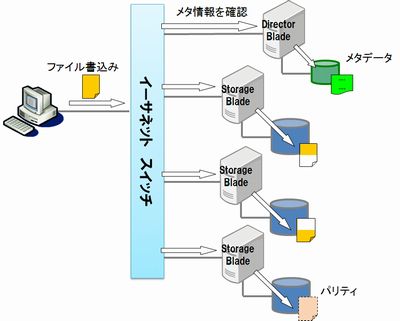
Panasas ActiveStorはPanFSストレージ・オペレーティングシステムによりパフォーマンスと耐障害性を両立したアプライアンス製品です。 メタデータサーバの役割を持つDirector Bladeとデータ領域にあたるStorage Bladeで構成されています。 インターコネクトはイーサネットを使用します。 サーバ側とクライアント側の両方を10ギガイーサネットにするのが望ましいですが、コスト面からクライアント側はギガイーサネットにするケースが多いです。 インフィニバンドには非対応ですが、性能は決して低くはありません。 ストレージの1ボリューム化はPanasas独自の方式で、Tiered Parity機能、いわゆるRAID-5のパリティにあたるものをストレージブレード間で持つため、一つのストレージブレードが壊れてもファイルシステムは保持されます。 運用中にストレージブレードの交換が可能なところもRAID-5に似ています。 実際のユーザによると、運用は非常に楽で、ディスク障害時は壊れたストレージブレードを交換するだけ、というアプライアンス製品ならではの特長があります。 コストはやや高めですが、高いパフォーマンスと高い可用性のため、リピータが多いストレージシステムでもあります。
GlusterFS
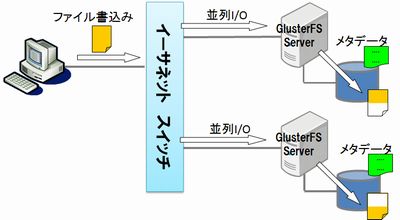
2011年にRedHatが買収し、2012年からRedHat Storage 2.0というオペレーティングシステムとして販売されています。オープンソースとして開発されているため、FedraやCentOS用のrpmも公開されており、手を出し易い並列ファイルシステムです。インターコネクトとしてインフィニバンドにも対応していますが、最新バージョン3.3では利用できなくなっています。メタデータサーバは不要です。ブリックと呼ばれる複数のデータ領域を1ボリューム化する際に、基本的な3つの方式があります。Lustreの様なStriped方式、ファイルを分解せずに分散配置するDistributed方式、ブリック間でミラーリングするReplicated方式、更にこれらの複合型方式に対応します。例えば、Replicated+Striped方式にすればスケーラビリティとの両立も出来ます。ファイルシステムコントロールの部分にFUSE(Filesystem in Userspace)を利用しているのでkernel依存性が低く、構築も比較的簡単です。製品版の価格はRHEL Server程度ですので、前述のGPFS、Panasasに比べれば低コストです。欠点としては、今回紹介した中では最も”若い“ファイルシステムで、インフィニバンドの対応が一旦停止したり、まだまだ開発段階にあることです。
各ファイルシステムの機能についてまとめると以下の通りになります。
並列ファイルシステムの機能比較
| 並列ファイルシステム | 使用できるインターコネクト | メタデータサーバの要・不要 | 1ボリューム化の方式 | 耐障害性 | 構築・運用の難易度 | 導入コスト |
|---|---|---|---|---|---|---|
| Lustre | イーサネット インフィニバンド |
要 | ストライピング 分散 |
中(*1) | 難 | 安 |
| GPFS | イーサネット インフィニバンド |
不要 | ストライピング 分散 レプリカ |
高 | 中 | 高 |
| Panasas ActiveStor | イーサネット | 要 | RAID-5風(*2) | 高 | 易 | 高 |
| GlusterFS | イーサネット インフィニバンド |
不要 | ストライピング 分散 レプリカ |
高(*3) | 中 | 中 |
(*1)別途、HAクラスタ構成を構築する必要があります。
(*2)RAID-5の様にパリティを持ちますが、分かり易くそう表現しただけで、RAID-5と全く同一ではありません。
(*3)1ボリューム化の方式に依存します。
GPFS、Panasasは高価ですが、Lustreに追随する高速性能と、対価に値する機能性と耐障害性を持っています。 GlusterFSはまだまだこれからのイメージがありますが、RedHatが開発を担当したことで将来に大いに期待したいところです。
並列・分散ファイルシステムはホットなテーマの一つで、今回紹介した他にもCeph、OrangeFSなどが開発中です。 また、Lustreについては、主なエンジニアが集まり設立したWamcloudという会社がありましたが、2012年7月にインテルに買収されてしまいました。 まだ業界は混迷としており、着地点が見えないのが現状の様です。